神经网络的基本骨架、卷积操作、卷积层、最大池化层、非线性激活、线性层、Sequential、损失函数、优化器
1. 神经网络的基本骨架
官方文档:https://pytorch.org/docs/stable/nn.html
继承nn.Module
1 | from torch import nn |
2. 卷积操作
官方文档:https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
stride的作用是卷积核每次移动的步长
padding的作用是在输入的边缘补0
1 | import torch |
3. 卷积层
官方文档:https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
示例:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
in_channels:输入数据的通道数(例如,RGB图像的通道数为3)。out_channels:卷积核的数量,即输出的特征图数量。kernel_size:卷积核的大小,可以是一个整数或元组(如3或(3, 3))。stride:卷积操作的步长,默认为1。padding:在输入的边缘补充的像素数,以控制输出的大小。dilation:卷积核元素之间的间距,默认为1。bias:是否添加偏置项,默认为True。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37from torch.utils.tensorboard import SummaryWriter
from torch import nn
import torch
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataload = DataLoader(dataset, batch_size=64, shuffle=True)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
model = Model()
print(model)
writer = SummaryWriter("logs")
step = 0
for data in dataload:
imgs, targets = data
output = model(imgs)
# print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
writer.close()
4. 最大池化层的使用
官方文档:https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
是下采样操作,用于减少数据的空间尺寸(宽度和高度),从而降低计算复杂度。池化层只保留局部区域的最大值,忽略其他较小的值,从而保留最显著的特征,抑制不重要的噪声。
参数ceil_mode决定了如何处理池化窗口的边界情况,
ceil_mode=False(默认):输出尺寸的计算采用floor(向下取整),即舍去小数部分。这意味着在池化过程中,如果最后的窗口未完全覆盖输入的边界部分,则该窗口会被忽略。- **
ceil_mode=True**:输出尺寸的计算采用ceil(向上取整),即向上取整处理。在这种情况下,最后的池化窗口可以扩展到输入边界,即使该窗口未完全覆盖输入边界的数据也会参与计算。这会增加输出的尺寸。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42from torch.utils.tensorboard import SummaryWriter
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
# 5x5的输入
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
input = input.reshape(1, 5, 5)
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataload = DataLoader(dataset, batch_size=64, shuffle=True)
writer = SummaryWriter("logs")
class Model(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, x):
output = self.maxpool(x)
return output
model = Model()
# output = model(input)
# print(input.shape)
# print(output.shape)
step = 0
for data in dataload:
imgs, targets = data
print(imgs.shape)
output = model(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step += 1
writer.close()
5. 非线性激活
官方文档:https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
非线性激活函数使得神经网络能够学习和逼近复杂的非线性关系。
1 | from torch.utils.tensorboard import SummaryWriter |
6. 线性层
线性层官方文档:https://pytorch.org/docs/stable/generated/torch.nn.Linear.html#torch.nn.Linear
线性层可以改变数据的维度,例如在卷积神经网络中,将卷积层的输出展平(flatten)后通过线性层,将特征映射到最终的类别空间或回归目标空间。
1 | import torchvision |
7. Sequential使用
用于将多个层按顺序组合在一起。它的主要用途是简化模型的定义,使代码更加简洁和易读。
CIFRA10数据训练的模型结构如下图: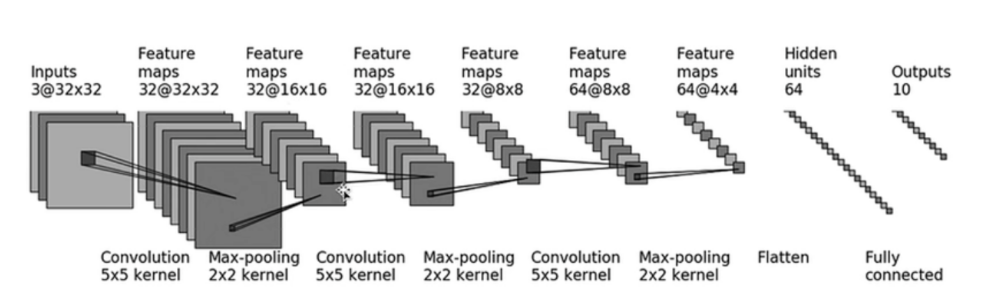
1 | from torch import nn |
8. 损失函数
计算和实际输出之间的差距
为反向传播提供依据
1 | import torch |
在神经网络中如何使用损失函数:
1 | from torch import nn |
9. 优化器
根据计算得到的梯度来更新模型的参数,以最小化损失函数
1 | from torch import nn |